INTRODUCTION
I am a research scientist with a cross-disciplinary background in signal processing, pattern recognition, numerical computation, and acoustic-phonetic modelling of human speech. I share the view that the theoretical and experimental study of spoken language, our distinctive means of communication, is not simply an adjunct to some other discipline as it has sometimes been portrayed. Instead, it is a field of scientific investigation in its own right with relevant applications such as in security access with speech-speaker recognition, in education with text-to-speech synthesis or, closer to current challenges, in defence with forensic voice comparison.
My research interests revolve around the acoustical dynamics and speaker-dependent variability of vowels and diphthongs, and the application of this information to problems in speech automation. Three questions continue to motivate my research contributions, most of which consist of methods and their evaluations: (1) How do we reliably and efficiently estimate formant-frequencies of the human vocal-tract from the acoustic speech signal?; (2) How do we model vowels and diphthongs in order to uncover systematicity in their spectro-temporal dynamics?; and (3) How do we characterise speech and speaker variability using the cepstrum, the acoustic parameter of choice in automatic speech technology but one which, unlike the formant, is not readily amenable to phonetic or articulatory interpretations?
CONTENT
This web-page contains links to my Publications which I have divided according to my three research areas outlined above. In the future, I intend to add links to my numerical data (formant-frequencies and cepstral coefficients) obtained from vowels and diphthongs spoken in American, Australian and British English.
You will also find below a summary of my past and current Academic Postings, a list of selected Under-/Post-graduate works completed under my supervision, an overview of my Research Projects, and a Brief History of my transition from Speech Engineering to Acoustic-Phonetics Research.
PUBLICATION LINKS
- Speech Signal Parameterisation for acoustic-phonetic, acoustic-articulatory and acoustic-prosodic analyses;
- Speech-Speaker Variability in formant/cepstral spaces; implications in speech recognition & forensic voice comparison.
- Spectro-Temporal Dynamics & Linear-Scaling Methods in formant-frequency space of vowels & diphthongs;
ACADEMIC BACKGROUND & POSTINGS
I carried out my PhD research on mathematical modelling of the spectro-temporal dynamics in Australian English diphthongs, while holding a full-time scholarship at the Australian National University (Institute of Advanced Studies, Research School of Physical Sciences & Engineering). I then accepted a postdoctoral fellowship at the Institut National de la Recherche Scientifique in Canada, prior to taking up a senior lectureship at the Canberra campus of the University of New South Wales (UNSW).
For over a decade at UNSW, I lectured and tutored a range of subjects (e.g., Algorithm Design, Computer Programming, Numerical Methods for Engineers, Statistical Research Methods, Computer Speech Processing), and acted as Deputy Head for Research in the School of Computer Science. I also held visiting professorships (with full-year teaching and research duties) at the University of Tsukuba in Japan, the American University of Paris in France, and Lund University in Sweden. Just for a change, I spent some time in Saudi Arabia lecturing Academic English and Critical Thinking at Prince Sultan University in Riyadh and King Fahd University of Petroleum & Minerals in Dammam.
Presently, I am a Visiting Professorial Fellow in the Speech & Language Laboratory at the Australian National University in Canberra, Australia. I am also a Senior Consultant for the Forensic Speech & Audio Laboratory at J.P. French International in York, England, where I had the privilege of working for two years as a research scientist.
TITLES OF SELECTED UNDER-/POST-GRADUATE WORKS COMPLETED UNDER MY SUPERVISION
- BSc (1993), "A comparison of distance measures and dynamic time warping techniques for speaker verification” by A.H. Green
- BSc (2005), "Mox Blox: Using 3D technology to revive a classic" by N. Jouannem
- BSc (2018), "Visualising tongue shapes estimated from vowel formant-patterns: A pilot study" by A. Al-Fayez
- MSc (1994), "Back-front classification of vowels using cepstral coefficients” by C. Piscopo
- MSc (1994), "A study of correlations between low-order cepstral and RMS log-spectral distances” by P. O'Donohue
- MSc (1996), "Computer recognition of Australian English vowels based on multi-speaker spectrographic data” by K. Kumar
- PhD (1998), "An acoustic-phonetic and articulatory study of speech-speaker dichotomy" by P. Mokhtari
- PhD (2006), "Forensic speaker analysis and identification: A bayesian approach anchored in the cepstral domain" by M.K. Joopari
- PhD (2010), "Auditory-acoustic characterisation of variability in the operatic vowel", by T.J. Millhouse
RESEARCH PROJECTS
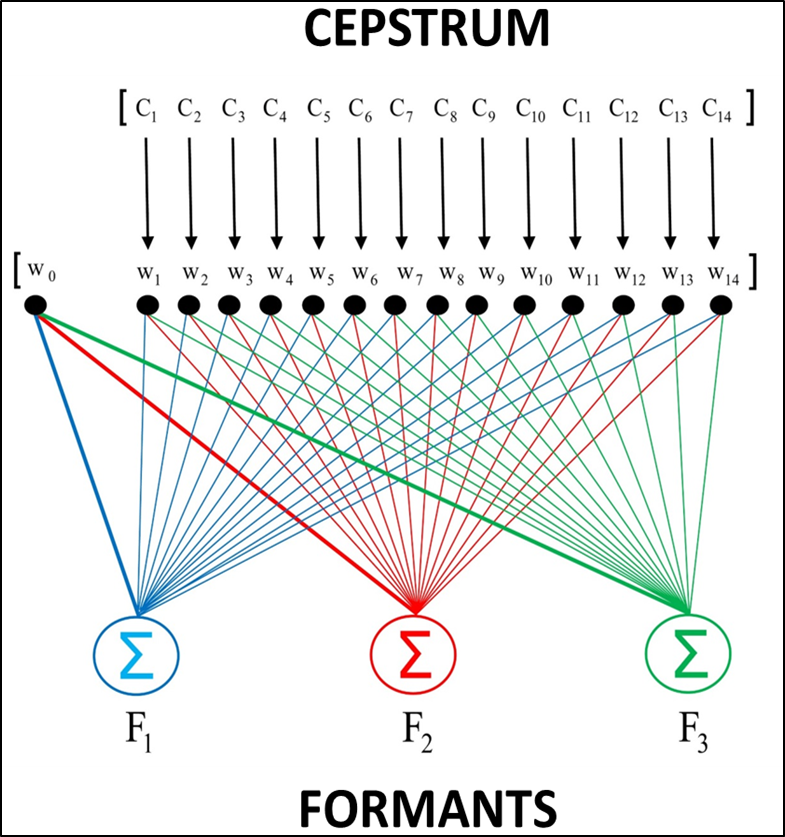
Cepstrum-to-Formant Estimation. My research endeavours clearly depend on being able to measure formant frequencies from the speech signal with a certain degree of robustness. However, even the best methods available to date are prone to catastrophic errors. I have therefore been investigating a potentially more robust approach based on the cepstrum. This acoustic parameter cannot readily be decomposed into formants, but it can be extracted without measurement uncertainties. The solution depicted in the figure shown above at right consists of a multiple-linear regression model to map cepstral coefficients onto formant frequencies. Although the relationship between cepstra and formants is intrinsically nonlinear, there is some promising evidence of linearity in local regions of those two parameter spaces. Using cepstral representations of individual vowels and voiced fillers extracted from spontaneous speech, I have found formant estimates to never be wrong even in cases where they are not highly accurate. These fndings warrant further evaluation of the apparent robustness in cepstrum-to-formant estimation via linear regression.
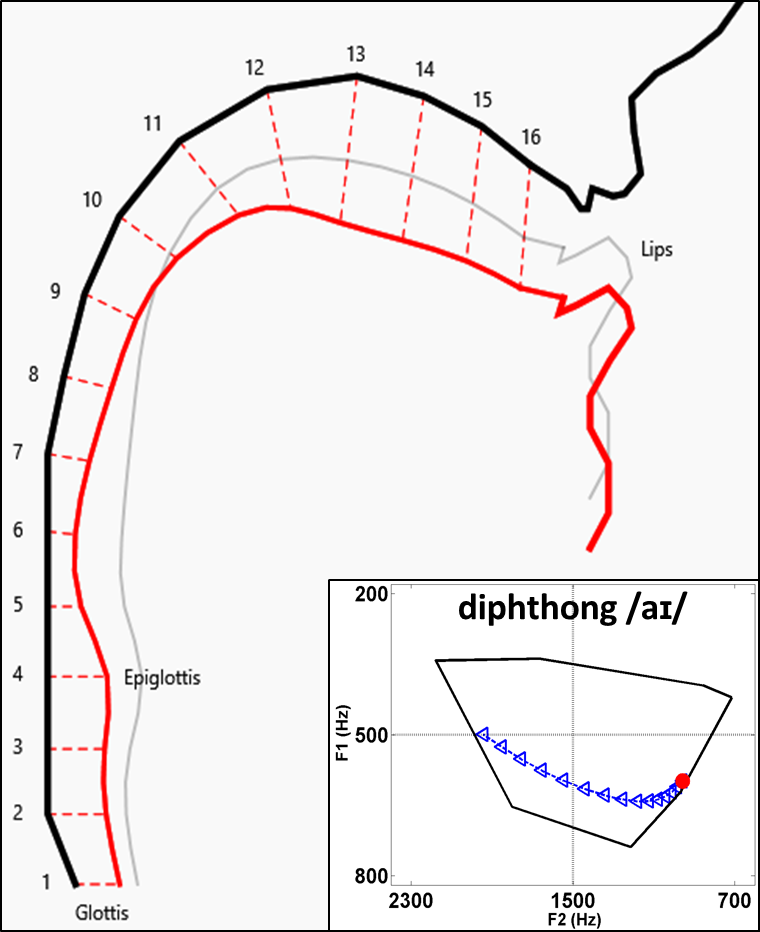
Modelling Diphthong Dynamics. My strong interest in diphthong-formant transitions arose from my PhD work, which focused on mathematical representations capable of yielding meaningful interpretations in articulatory-phonetic terms. The figure shown above at left is a brief example. It portrays the tongue position at the start of an Australian English diphthong (/aI/), and its acoustic realisation is seen in the inlay graph as a nonlinear formant trajectory (blue-coloured) between two target regions of the acoustic-phonetic space. The (red-coloured) contour of the tongue body in the figure is actually predicted from formant-frequencies measured at onset of the diphthong movement - this is what is broadly called vocal-tract shape modelling. My long-term objective is to exploit the link between vocal-tract and formant movements as an explanatory basis for the time-dependent dynamics and the speaker-dependent variability of diphthongs.
Modelling Coarticulation. The aim of this project is to look for systematic effects of consonantal contexts on the relative positioning of vowels. A relevant question is whether the patterns of inter-vowel spacings for a given formant, named in short as vowel-formant ensembles (VFEs), are related to one another from context to context or from one time location to the next within a syllable. The key finding from American and Australian English data, is that all pairs of VFEs within and between contexts are linearly-scaled copies of one another. VFE scaling is therefore a powerful tool with which one can easily quantify the expansion or contraction effects of various contexts at any time-frame or across time-frames. It is conceivable that one could also "de-context" VFEs by inverting their scales in order to match the scale for some reference VFE. Future work will focus on further evaluations of the linear-scaling property using not only the traditional formant parameter but also the more easily-extracted cepstrum.
Sub-Band Cepstral Distance, Speaker Variability, Forensic Voice Comparison. I am concurrently involved in forensic voice comparison projects whose aim is to take advantage of locally-encoded spectral manifestations of speaker variability in the cepstral domain. To this end, I have been experimenting with a parametric form of the euclidean cepstral distance which affords the flexibility of selecting an arbitrary sub-band directly from full-band cepstral coefficients (CCs), thus obviating the computational cost of re-analysing the speech signal for every sub-band of interest. Spectral consistency is also preserved since sub-band cepstral distances are based on the same full-band CCs. These properties should facilitate a more systematic search of speaker-specific bands, especially those where between-to-within speaker variances are relatively large.
FROM SPEECH ENGINEERING TO ACOUSTIC-PHONETICS RESEARCH: BRIEF HISTORY
Encounter with Speech Signal Processing. The 70's were amazing times for the signal processing of speech: Some of the ground-breaking algorithms still in use today had already been developed, while many others were at an early stage of conceptualisation. I was therefore lucky to get in nearly on the ground floor when I became involved in speech processing in the early 80's. No formal training was then available in this new area of specialisation, but I had been taught the basics by Professor Athanasios Papoulis, a highly regarded theoretician of signal processing at the Polytechnic Institute of New York, and there was Rabiner and Schafer's "blue book", one of the first comprehensive references on digital processing of speech signals. What I was able to glean from the blue book gave me a solid knowledge base and enough confidence to secure, in 1982, an engineering position at Speech Technology Laboratory (STL) in Santa Barbara, California. For many years, this city blessed with a pleasantly mild climate was a world-renowned hub for speech scientists.
Encounter with Linear-Prediction Analysis, Vocal-Tract Shape Estimation, Basic Principles of Phonetics. During my engineering stint at STL from 1982 to 1985, I had the extraordinary fortune to gain invaluable technical skills and historical insights through my interactions with leading researchers in speech science and technology. I learned about speech synthesis and vocal-tract shape estimation from Dr Hisashi Wakita, the head of STL, who had done pioneering work in these areas. I studied the mathematical theory of linear prediction under the mentorship of Professor Augustine Gray. His classic book "Linear Prediction of Speech", co-authored with Dr John Markel, lays down the foundation for the digital model of speech production that led to quantum leaps in computer automation of speech analysis, synthesis and recognition. Professor Edith Johnson Trager taught me the basics of phonetics through her lively lectures at STL. This is when I began to marvel at phonetic transcriptions, and to wonder about phonetic invariance in the face of acoustic-parameter variability.
Encounter with Acoustic Phonetics. It is in 1983 during one of the seminars hosted by STL, that I understood the importance of acoustic-phonetic parameters and the challenge associated with their variability. The seminar speaker was Dr David J. Broad, Associate Director of the Speech Communications Research Laboratory established by his PhD supervisor, Professor Gordon E. Peterson (one of the pioneers in Speech Science). David had initially been approached to talk about exploiting acoustic-phonetic knowledge in the design of speech recognition systems. Since such knowledge presupposes a good grasp of the determinants of acoustic-phonetic parameter values, his seminar instead focused on two fundamental issues: (i) the multi-level sources of variability in the acoustic speech signal; and (ii) the need to disentangle their systematic and random components. These issues are still central to the search for robust models of speech and speaker variability.
David's seminar presentation was clearly a "eureka" moment, which caused a radical shift of my interests towards basic research. It also triggered our collaboration on a number of problems, one which continued for more than two decades despite the wide difference between Santa Barbara and Canberra timezones. It is worth noting the turning point of our efforts in acoustic-phonetic modelling of coarticulation effects: We uncovered that for a given speaker and formant-frequency, the pattern of inter-vowel spacings remains constant irrespective of the consonantal context or the time location within a syllable. It is the geometric similarity of such patterns which led us to the hypothesis that they should mathematically be tied together by linear-scaling relationships. In support of this hypothesis, we have found consistent evidence based on American and Australian English vowels produced in various consonantal contexts. Further research will be necessary to determine its applicability to a wide range of speakers and to vowel systems from other languages. It will also be valuable to test the hypothesis using the cepstrum as an alternative parameter that can automatically be extracted from the acoustic speech signal.
Sadly, David passed away in Santa Barbara on 6th October 2020. Quite apart from the extraordinary privilege of having been his longstanding collaborator in speech research, I will forever be grateful for his scholarly outlook and his true friendship!